LLM Optimization
LLM optimization is the practice of systematically improving LLM applications and agents across dimensions like quality, cost, and latency. For single-turn LLM applications, optimization typically focuses on prompt quality, model selection, and token efficiency. Agent optimization goes further: because agents make multiple LLM calls, invoke tools, and follow multi-step reasoning chains, they introduce additional challenges around debugging complex execution paths, reducing compounding latency, and controlling costs that scale with each reasoning step. Both require specialized tooling because LLM behavior is non-deterministic, costs scale with token usage, and quality can only be measured with semantic evaluation rather than unit tests.
Effective LLM optimization starts with visibility. Tracing captures token counts, latency, and execution details for every LLM call, revealing where costs and bottlenecks are. Evaluation measures output quality with LLM judges, providing a baseline to track whether changes actually improve performance. Prompt optimization automates the process of improving prompts algorithmically, replacing manual trial-and-error with systematic, data-driven iteration.
MLflow provides the complete open-source toolkit for LLM optimization: tracing for cost and latency visibility, evaluation for quality measurement, prompt optimization for algorithmic prompt improvement, and an AI Gateway for cost management, compliance, and governance across LLM providers.
Quick Navigation:
Why LLM Optimization Matters
LLM applications face unique optimization challenges that traditional software profiling and testing can't address:
Runaway Costs
Problem: Token costs scale with usage, and multi-step agents can make dozens of LLM calls per request. Without visibility, API bills grow unpredictably.
Solution: Tracing captures token usage per span so you can find expensive operations, and an AI Gateway enforces rate limits and budget controls across providers.
Quality & Reliability
Problem: LLM applications can produce hallucinations, irrelevant responses, and degraded outputs that undermine user trust, and traditional testing can't catch these issues.
Solution: Evaluation with LLM judges continuously assesses quality dimensions like correctness, relevance, and safety across every response, catching regressions before users report them.
Slow Response Times
Problem: LLM calls add hundreds of milliseconds to seconds of latency per request. Agent workflows with multiple sequential calls compound this significantly.
Solution: Per-span latency tracing identifies bottlenecks so you can parallelize calls, cache repeated queries, or use faster models for non-critical steps.
Inefficient Iteration
Problem: Manual prompt engineering is slow, inconsistent, and plateaus quickly. Engineers can't systematically identify which prompt changes improve quality.
Solution: Automated prompt optimization uses algorithms to systematically improve prompts across hundreds of examples, replacing guesswork with measured improvement.
LLM Optimization Techniques
LLM optimization spans several complementary strategies. The most effective approach combines visibility (tracing), measurement (evaluation), and systematic improvement (prompt optimization):
- Cost Optimization with Tracing: Capture token counts per span to identify the most expensive operations in your pipeline. Common wins include shortening verbose prompts, eliminating redundant LLM calls in agent loops, routing simple queries to smaller models, and caching repeated requests.
- Quality Optimization with Evaluation: Use LLM judges to measure output quality across dimensions like correctness, relevance, safety, and groundedness. Establish a quality baseline, then measure the impact of each change. Automated evaluation replaces subjective spot-checking with systematic measurement.
- Prompt Optimization: Replace manual prompt engineering with algorithms that systematically improve prompts across training data. Optimizers like GEPA analyze failure patterns, generate improved variants, and select the best performer automatically.
- Cost Governance with AI Gateway: Route LLM requests through a centralized gateway with rate limiting, budget controls, fallback routing, and unified credential management. Track usage and costs across all providers from a single dashboard.
- Production Monitoring: Run LLM judges continuously against production traces to catch quality regressions, cost spikes, and latency degradation before users report them.
Common Use Cases for LLM Optimization
LLM optimization applies across the full lifecycle of LLM applications:
- Reducing agent costs: Multi-step agents can make many LLM calls per request. Use tracing to identify unnecessary reasoning loops and redundant tool calls, then optimize the agent's prompts and logic to reduce token usage.
- Improving RAG quality: Retrieval-augmented generation pipelines depend on both retrieval and generation quality. Use evaluation with groundedness and relevance judges to measure end-to-end quality, then iterate on chunking, embedding, and generation prompts.
- Optimizing prompts at scale: Instead of manually tweaking prompts for each feature, use prompt optimization to algorithmically improve prompts across hundreds of examples with full tracking and versioning.
- Model selection and routing: Not all queries need the most expensive model. Use tracing and evaluation to identify which queries can be routed to cheaper, faster models without sacrificing quality, and implement routing through the AI Gateway.
- Latency optimization: Use per-span latency tracing to find bottlenecks, then apply streaming, caching, parallelization, or model downsizing to reduce response times.
- Production quality monitoring: Run LLM judges continuously against production traces to detect quality regressions, hallucination spikes, and cost anomalies before they impact users.
How to Implement LLM Optimization
MLflow provides the complete open-source toolkit for LLM optimization. Start with tracing to gain visibility, add evaluation to measure quality, then apply targeted optimizations based on what the data shows.
Step 1: Enable tracing for cost and latency visibility
import mlflowfrom openai import OpenAI# Enable automatic tracing for OpenAImlflow.openai.autolog()# Every LLM call is now traced with token counts,# latency, prompts, and responsesclient = OpenAI()response = client.chat.completions.create(model="gpt-4.1",messages=[{"role": "user", "content": "Summarize MLflow"}],)# Search traces to analyze cost and latency patternstraces = mlflow.search_traces(experiment_ids=["1"])for trace in traces:print(f"Tokens: {trace.info.total_tokens}")print(f"Latency: {trace.info.execution_duration_ms}ms")
Step 2: Evaluate quality with LLM judges
import mlflowfrom mlflow.genai.scorers import (Correctness,RelevanceToInput,Safety,)# Evaluate LLM outputs with built-in judgesresults = mlflow.genai.evaluate(data=mlflow.search_traces(experiment_ids=["1"]),scorers=[Correctness(), # Are responses factually correct?RelevanceToInput(), # Are responses relevant to the query?Safety(), # Are responses free of harmful content?],)# View results in the MLflow UI or programmaticallyprint(results.tables["eval_results"])
With tracing and evaluation in place, you have the visibility needed to apply targeted optimizations: shorten prompts to reduce costs, run automated prompt optimization to improve quality, route through the AI Gateway for cost management, compliance, and governance, and monitor production quality with continuous evaluation.
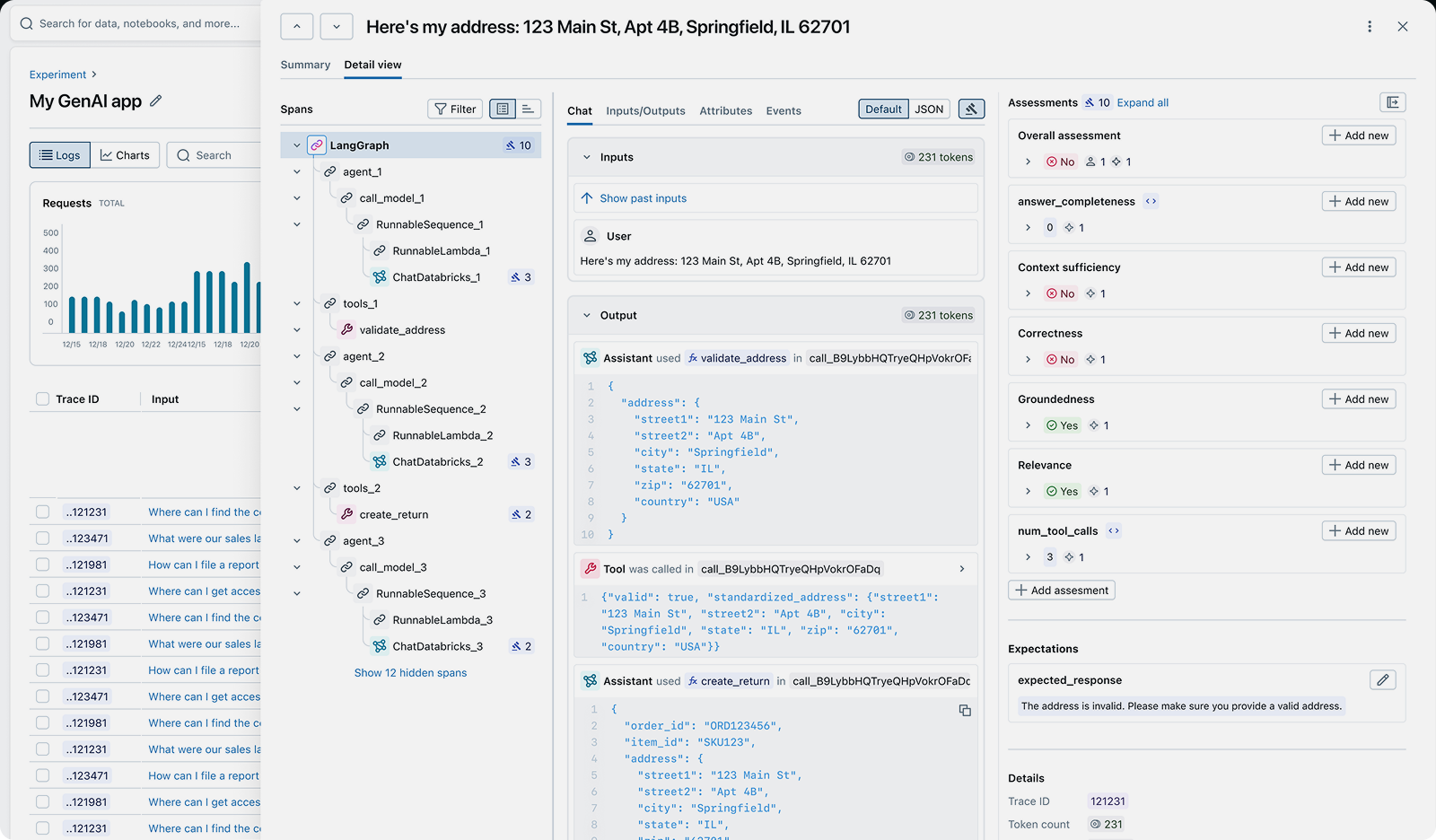
MLflow captures traces with token counts, latency, and full execution context for every LLM call
MLflow is the largest open-source AI engineering platform, with over 30 million monthly downloads. Thousands of organizations use MLflow to debug, evaluate, monitor, and optimize production-quality AI agents and LLM applications while controlling costs and managing access to models and data. Backed by the Linux Foundation and licensed under Apache 2.0, MLflow provides a complete LLM optimization toolkit with no vendor lock-in. Get started →
Open Source vs. Proprietary LLM Optimization
When choosing tools for LLM optimization, the decision between open source and proprietary platforms has significant implications for cost, flexibility, and data ownership.
Open Source (MLflow): With MLflow, you maintain complete control over your optimization data and infrastructure. Trace data, evaluation results, and prompt versions stay on your own systems. There are no per-seat fees, no usage limits, and no vendor lock-in. MLflow integrates with any LLM provider and agent framework through OpenTelemetry-compatible tracing.
Proprietary SaaS Tools: Commercial optimization and observability platforms offer convenience but at the cost of flexibility and control. They typically charge per seat or per trace volume, which becomes expensive at scale. Your trace data and evaluation results are sent to their servers, raising privacy and compliance concerns. You're locked into their ecosystem, making it difficult to switch providers or customize workflows.
Why Teams Choose Open Source: Organizations optimizing LLM applications at scale choose MLflow because it provides production-grade tracing, evaluation, prompt optimization, and cost management, compliance, and governance without giving up control of their data, cost predictability, or flexibility. The Apache 2.0 license and Linux Foundation backing ensure MLflow remains truly open and community-driven.